

Sometimes, you might not want search engines to crawl or index some pages of your website – for example if they contain confidential documents, are only meant for registered users or are out-of-date.
Normally, you can achieve this by implementing approaches such as meta robots tags, robots, or 301 redirects. Unfortunately, different search engines follow different rules – and this is especially the case with Baidu. If you want to introduce your site to Baidu, you have to consider what Baidu supports. In this blog post I will share a summary of what Baidu supports compared to Google.
Canonical tag

You should use a canonical tag when you have two very similar or duplicate pages and want to keep both of them, but do not want to be penalised for duplicate content issues. Adding a canonical tag in the source code will tell the search engines which page is the correct version to index.
Both Baidu and Google support canonical tags, but do not 100% comply with them. It is recommended to use canonical tags only on duplicate or very similar pages. If Baidu finds out that your site does not use canonical tags correctly, it will simply ignore all canonical tags on your site.
Meta robots
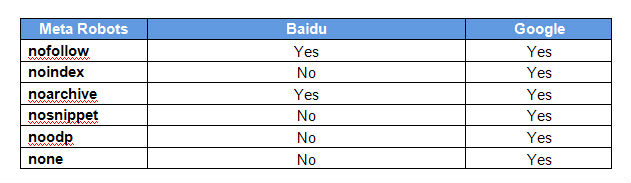
By adding meta robots to the source code, you can tell robots how to handle certain pages on your site, such as disallowing search engines from following certain links, indexing a page or showing snippets in the search engine result pages. At the moment, Baidu only supports “nofollow” and “noarchive”. I believe Baidu does not yet support the rest. This means that even if you implemented “noindex” on a page, Baidu will still index it. On the other hand, Google supports all of the above.
301 redirect

301 redirects are used for permanent URL redirection. When you have a page that you do not want to use anymore, you can use a 301 redirect to point to a new page. Both Baidu and Google support 301 redirects.
Robots.txt

Robots.txt is a text file placed in the root of the website. It is required when you want to have some content on your site excluded from the search engines. Both Baidu and Google support Robots.txt.
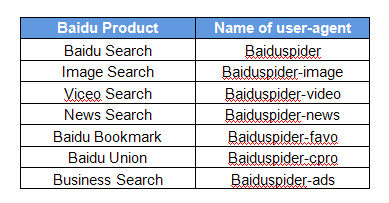
Below is the list of Baidu Spiders. You can disallow some of them by adding corresponding commands in Robots.txt. For example, if you want Baidu to only crawl the video files in the folder www.yourdomain.com/video/ , you can add this in the Robots.txt:
User-agent: Baiduspider
Disallow: /
User-agent: Baiduspider-video
Allow: /video/
HTTP and HTTPS

I also want to mention Hypertext Transfer Protocol Secure (HTTPS). As opposed to Google, Baidu does not index HTTPS pages. To get the content indexed, Baidu advises webmasters to create a corresponding HTTP page with same content as the HTTPS page and to redirect Baidu Spiders to the HTTP page. Then Baidu will be able to index that HTTP page.
Below is how Baidu cached Alipay. Baidu cached its HTTP page.
But visitors will be redirected to the HTTPS page:
Personally, I do not think this is a very good method. Since Google indexes HTTPS pages, this method might result in a duplicate content issue with Google. So if you have some content that may need to be indexed by both Google and Baidu, I suggest using only a HTTP page.








10 responses
Hi Yao
Thanks for the above information. I agree baidu does not seem to index HTTPS sites , however only those that have extremely high traffic should even consider doing this as it seems to hurt smaller sites. I believe the main reason behind this because it is also not common for Chinese sites to be HTTPS since most payment methods are done via mobile QR codes such as AliPay, so payment details are never really provided over websites.
Hope this adds value to your post!
Hi Devesh, thanks for your comment. Baidu said officially they don’t index Https pages at the moment. 🙂
Thank you very much. I have added sitemap and it started showing the crawls and indexed pages. 🙂
Cool 🙂
Could someone please help get my website (above) crawled by Baidu
Thank you
Joseph
Hi Yao,
Is this article still up to date? I have heard that as of May 25th Baidu actually prefers https over http but have found little information to confirm.
Appreciate any updates,
Sean
Hi Sean,
Thanks for your reply. Yes, Baidu official announced they can index HTTPS pages on 25th May, and they prefers HTTPS pages if both HTTP and HTTPS pages exist.
Thanks for your comments. This updated the article. 🙂
Best,
Yao
Hello all, it seems that Baidu can’t recognize the rel=”canonical” for the moment. Instead of this attribute, we could use rel=”index”. Thanks! Veronique
Hi, ours is a multi-lingual site with simplified Chinese contents. Over 2000 pages have been site mapped by Baidu, but only three (3) have been indexed by Baidu. What could be the problem?
Hi Ubong,
Thank you for your question! Yao isn’t around anymore but I hope I can help instead. Obviously we can’t diagnose the problem without investigating your website, but here are some common reasons why Baidu doesn’t index websites properly:
– Slow indexation for multilingual websites is a common issue on Baidu because Baidu does not view multilingual websites favourably. If your website has different country folders containing non-Chinese content, Baidu will think that your website is not aimed at Chinese users and will tend to index it much slower.
– Another big reason could be the website hosting location. If your website is not hosted in mainland China, Baidu will crawl and index it much slower (even websites hosted in Hong Kong and other regions near China get crawled much slower).
– Other potential reasons include a low number of inbound links (backlinks), poor website structure, your sitemap not having been submitted, and your website being new.
– Any of these factors can cause Baidu to take a long time (even several months) to crawl and index a website.
I hope that helps!
We can look into your website to identify exactly what’s going on, if you like. If that’s something you’re interested in, then please let me know and I’ll put you in touch with our friendly Business Solutions team 🙂
Thanks,
Elin