How long has it been since you last received an email that came out as absolute gibberish? I do not exactly remember myself, but it has been a long time. There used to be hundreds of different encodings for storing and indexing text on the internet. Since these encodings were different, they were not as such compatible with one another. “For example, on some PCs the character code 130 would display as é, but on computers sold in Israel it was the Hebrew letter Gimel (ג), so when Americans would send their résumés to Israel they would arrive as rגsumגs”, Joel Spolsky explains on his software blog.
Unicode was invented to solve this problem by encoding all human languages and making it universal as its name implies. So basically, according to Senior International Software Architect at Google, Mark Davis: “The more documents that are in Unicode, the less likely you will see mangled characters (what Japanese call mojibake) when you are surfing the web.”
The latest figures from Google’s annual survey of the percentage of the webpages in their index that are in different encodings reveal another significant upward move for Unicode. It now accounts for more than 60% of all web encodings, which is indeed good news to the many of us who enjoy translation services that allow us to find information in almost any language. Subsequently, this helps content-providers such as marketers expand their potential audiences.
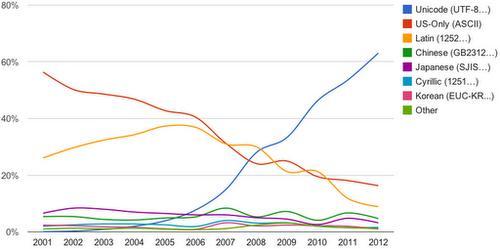
*Your mileage may vary: these figures may vary somewhat from what other search engines find. The graph lumps together encodings by script. We detect the encoding for each webpage; the ASCII pages just contain ASCII characters, for example.
Google has long been using Unicode as the company’s internal format for all the text it searches and processes and will soon be updating to the newest Version 6.1 with over 110,000 individual characters. According to Mark Davis, the search giant’s unified index probably would not exist had it not been to Unicode. Or as he puts it himself: “(…) it’d be a bit like not being able to convert between the hundreds of currencies in the world; commerce would be, well, difficult.”
Immanuel Simonsen
Latest posts by Immanuel Simonsen (see all)
- Is Baidu losing its crown in China? - July 31, 2015
- Global logistics brand DHL eyes Chinese e-commerce growth - July 27, 2015
- VKontakte To Launch Rival To Instagram - July 21, 2015

