
It was not that easy; just to walk in and become a contender in the Turkish internet market… blatantly squaring off against the virtual-market monopoly of the 15 years-established search engine Google in Turkey….but Yandex was very determined to be successful. Its target is to corner 20-25% of the search traffic, bullish figures when we consider that Google is almost unchallenged as the country’s predominant search engine of choice.
Turkey is the first non-Slavic, international market targeted by Yandex for expansion, and the main pilot project for the company. With a population of 80 million and an internet audience of over 36 million, Turkey is an attractive market for Yandex.
There was naturally a linguistic barrier for this new non-Slavic test market. But Yandex thought if it could achieve the target in Turkey, it could then expand and succeed in other countries, despite the seemingly insurmountable, linguistic and cultural differences. This, then, was a serious challenge the Russian search engine giant.

Google works in the same way in Turkey as it works in any other country-with no adaption for any linguistic nuances. This causes fundamental faults during the searches especially for an Altaic language, written with the (albeit, altered version of) Latin alphabet, such as Turkish. But Google users have their own habits now, and seem to work out how to find what they are looking for. However as each language uses different alphabets, different language characteristics require more intelligent and customised search engines to overcome such language-oriented problems.
Multi-alphabet data tends to lead to misspelling or typos in both search queries and documents.The Turkish alphabet is a Latin-based alphabet consisting of 29 letters, a certain number of which Ç, Ğ, ı, İ, Ş, and Ü were derived from the Latin alphabet with the addition of diacritical marks for the phonetic requirements of the language. For Turkish internet users, most of the typing errors occur with these special Turkish characters.
Many users type without these special characters because of speed, laziness or simply being used to using non-Turkish keyboards. And unfortunately casual typos can result in a drastic loss of meaning in Turkish. These special characters differ from, for example, accents in French or Spanish, and the words can mean something completely different if the wrong character is used. So I wondered: “is Yandex smart enough to bridge this gap in meaning?”
Yandex and Google – head to head
Round one
I wanted to test this on Google and Yandex, so I picked my pilot words: Yasama (legislation) and Yaşama (living). As you can see, the difference between them is only one derived character.
When I typed Yasama on Google, the Google predictive search field suggested only the terms related to legislation. So Google is not, yet, smart enough to figure out that this could be a mistyping error in Turkish.
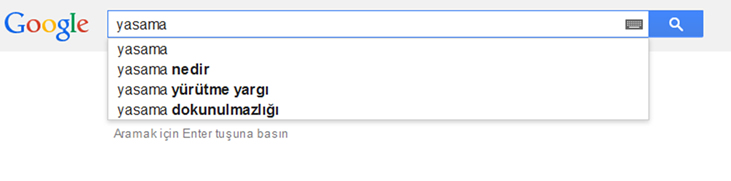
On the other hand, checking the word “yasama” on Yandex, the predictions were pretty savvy. Yandex not only suggested the other form of the word as well as the word itself (legislation) but also was smart enough to suggest couple more words about “Yaşama” (living) as it is a more likely to be a search query:

Yandex 1 – 0 Google
Round two
So Yandex won against Google in the first round. Now I was more curious about the search volumes. If Yandex was clever enough to suggest typo alternatives with some popular searches, the next step for me was to check the search volumes for these words on both search engines. Cards on the table, the result of the search volume did not impress me as much as the first round:
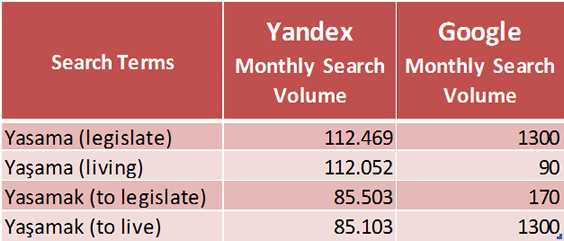
When it comes to the search volumes, Yandex results lead us to a more confused picture. I checked both words in noun and verb forms – just to be sure- and the Yandex-Wordstat seemed to not recognise the fact that they are different words and counts them just as typos. But the Google Adwords Keyword Planner seems to be picking up the difference in the users’ behaviour. Yaşama (living) on its own would not be the most popular search term and Google thinks so as well. But on the other side “to live” has bigger search volume than “to legislate” which is much more likely to be sought out on the Internet.
I should point out that Yandex is not that popular yet and the usage rate is not more than 5% in Turkey, so the search volumes can clearly be misleading. There might not be enough input to separate between the mistyping and original word yet in the search volume results, but in the search enquiry there is an obvious difference.
Yandex 1 – 1 Google
Round three
The Turkish language has more linguistic curve balls for us though. The structure of the Turkish language is a morphologically rich, agglutinative language: words are formed by joining phonetically unchangeable affix morphemes to the stem. Also, to add an additional linguistic headspin, Turkish has a more complex structure than most other agglutinative languages, for instance just one verb can have thousands of different conjugations.
The table below shows how verbs can have different forms in Turkish. 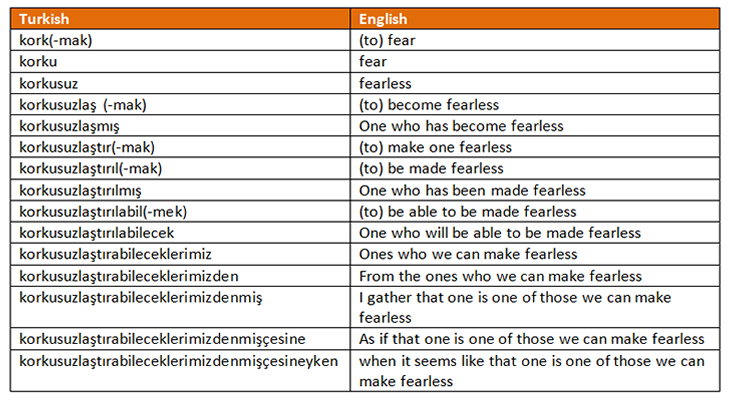
Now the 3rd step is how Yandex and Google cope with these different forms and meanings of the words.
Let’s imagine that someone is going to Istanbul and wants to see their options. So I entered the search term “İstanbul’a gidiyoruz” (“We are going to Istanbul”) on Google. Especially in the first results, the search term verb is mainly in the exact form, about people who are going to Istanbul. And in the second or third pages we can see some different results like “I am going, we go, (mainly added suffixes for other subjects).
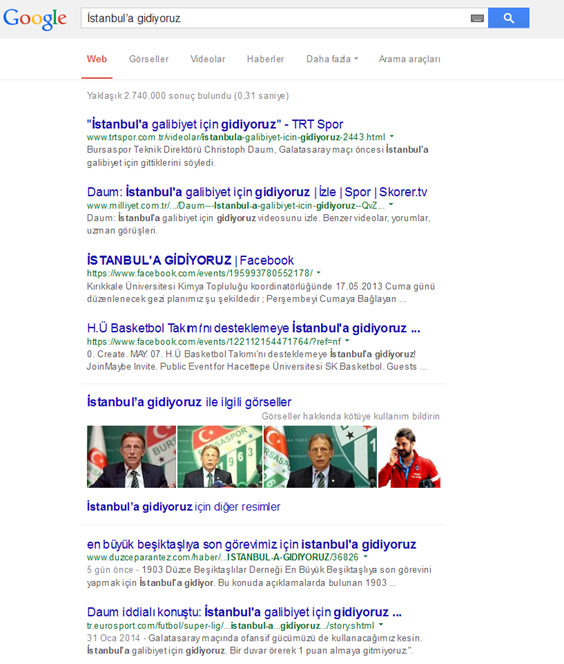
When I entered my search term on Yandex, you could easily see that Yandex can come up with different forms of the aforesaid verb related to “to go to istanbul” rather than the exact form “we are going”. So even on the first result page we could also see the different forms of the verb such as- “İstanbul’a nasıl gidilir” (how to go to Istanbul), “İstanbul’a gidince İstanbul’dan ne alınır” (what to buy in Istanbul when you go to Istanbul) etc.
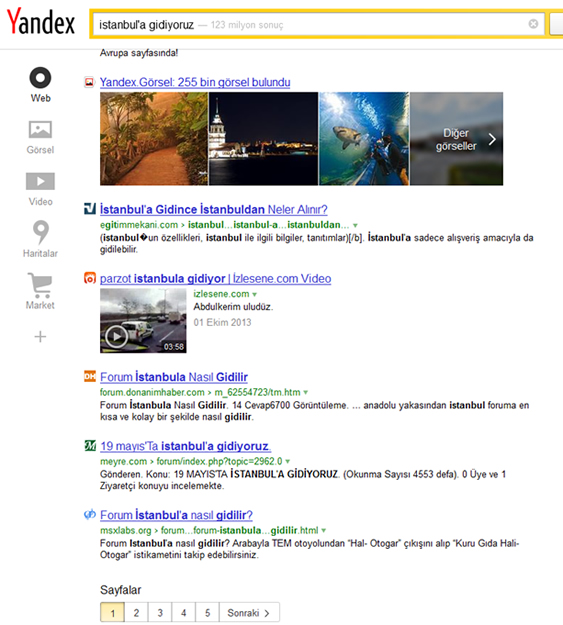
So, one more, time Yandex proved what a smart search engine it is when it comes to Turkish.
Yandex 2 – 1 Google
Round four
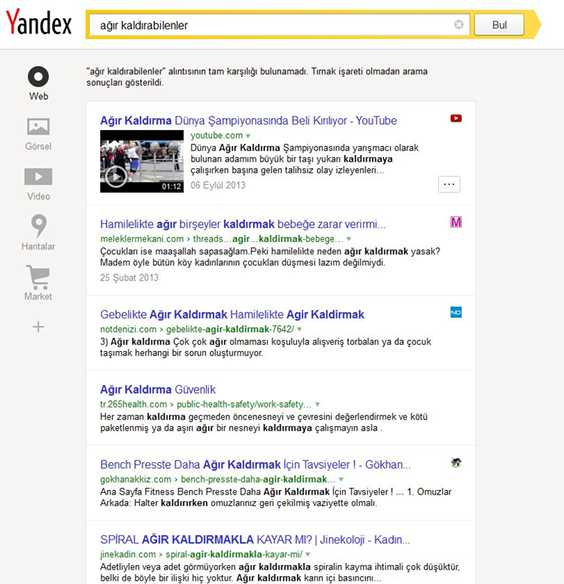
There was one more thing I wanted to check which is about both word morphemes and synonyms. I picked another example term “ağır kaldırabilenler” – meaning “the ones who can lift heavy things”. This is the primary meaning of the word-which is more likely to be searched for. The secondary meaning is: “the ones who can overcome difficulties”. And a possible third meaning is “the things which can take on more than their capacity”.
Yandex again came up with a wide variety of word-forms in terms of morphemes, such as –to lift, -lifting, -by lifting. Plus all the results were about heavy lifting mainly in health issues. In this result of Yandex showed the different forms of the word yet the same meaning. And in the first 30 pages I could not see any other version with secondary or third meaning.
When I searched the term on Google I was not expecting to see many different forms anyway, but I was wondering which suggestions of forms Google would come up with: This time Google has completely let me down as only 4 results out of 10 on the first page were related to “heavy lifting”. All in all, this is the primary meaning and I expect more results in that topic. Secondary and even third meanings of the term were much more common results on Google and even the results related to heavy lifting were about technical issues rather than health issues, such as those found on Yandex.
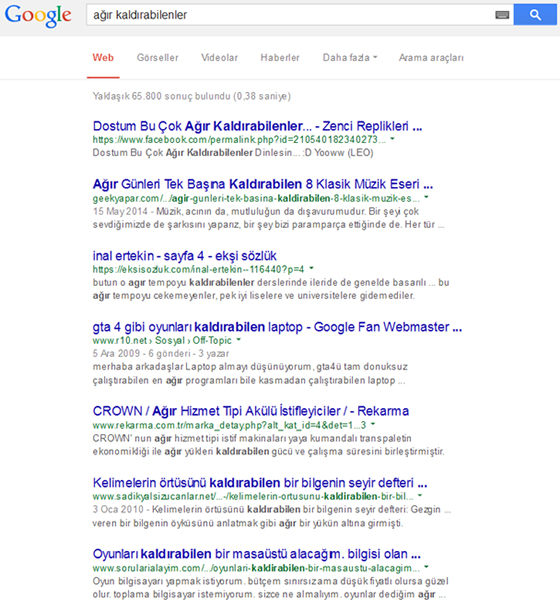
Final score: Yandex 3 – 1 Google
Can Yandex achieve its goal?
I am pretty convinced that Yandex can recognise and understand the Turkish word structure better – there are no grey areas here. Not only can it handle the structure of the morpheme words, it also recognises common typos based on the special characters in Turkish. So in the results, there is less chance of any form of the word you are searching for being omitted from the results. While Yandex helps us to find the result we are looking for, it also comes up with more possibilities (as mentioned, the words can be in thousands of different forms)- so this forces the user to wade through a lot more pages to reach the desired results.
Google, in comparison, shows fewer results-as the enquiries cannot be shown in different forms either exact or with simple linguistic differences, but less to look for- so it forces us to try a more permutations of searches to reach what we are looking for.
 Yandex is determined to succeed and to support that, it is also making an effort to appeal to local users. On the 84th anniversary of the Alphabet revolution in Turkey (when the national script was changed from Arabic to Latin) , Yandex showed its respect and sensitivity to the Turkish language and the brand appeared on that day without the non-Turkish character: X.
Yandex is determined to succeed and to support that, it is also making an effort to appeal to local users. On the 84th anniversary of the Alphabet revolution in Turkey (when the national script was changed from Arabic to Latin) , Yandex showed its respect and sensitivity to the Turkish language and the brand appeared on that day without the non-Turkish character: X.
Yandex is definitely taking great strides to provide a significantly better service to Turkish speakers looking for a bespoke search engine and deserves a bigger slice of the internet search market in Turkey. Of course, whether the market will take this up or not is still very much a question – watch this space!

Umay Jones
Latest posts by Umay Jones (see all)
- How to do international keyword research - May 21, 2018
- Head to head: Can linguistic advantages help Yandex beat Google in Turkey? - August 19, 2014





[…] Abänderungen und Doppeldeutigkeiten um als die Konkurrenz. Die komplette Untersuchung ist hier […]
[…] Yandex launched in Turkey but can it really compete with Google? We put them head to head to see which offers Turkish users the best experience. Who wins? […]
Interesting approach to compare SERPs with local specific.
What about city (local) results for both?
Hey Eugene, I guess you mean if both Yandex and Google show search volumes in city level, yes they do. And when I compare my pilot words on both, city level, Google shows the different results for different cities in Turkey but it seems no difference from city to another on Yandex – Wordstat!
Hello Umay!
It is very sad for Yandex.
In Russia according of cities we have different results for geo queries with Yandex. For example, “pizza” or “taxi” has differ SERP in Moscow or St. Petersburg.
In Google it is not always the case. Sometimes Google shows general SERP for all country
Good article. I’ll try Yandex next time when searching in Turkish.